|
|
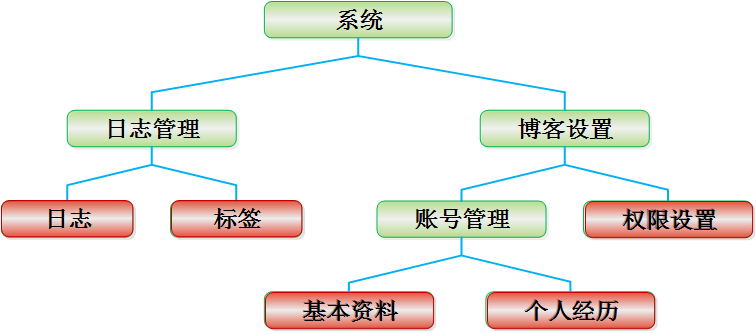
聚集索引的區(qū)別
聚集索引:物理存儲(chǔ)按照索引排序
非聚集索引:物理存儲(chǔ)不按照索引排序
優(yōu)勢(shì)與缺點(diǎn)
聚集索引:插入數(shù)據(jù)時(shí)速度要慢(時(shí)間花費(fèi)在“物理存儲(chǔ)的排序”上,也就是首先要找到位置然后插入),查詢數(shù)據(jù)比非聚集數(shù)據(jù)的速度快
聚集索引的區(qū)別
聚集索引:物理存儲(chǔ)按照索引排序
非聚集索引:物理存儲(chǔ)不按照索引排序
優(yōu)勢(shì)與缺點(diǎn)
聚集索引:插入數(shù)據(jù)時(shí)速度要慢(時(shí)間花費(fèi)在“物理存儲(chǔ)的排序”上,也就是首先要找到位置然后插入),查詢數(shù)據(jù)比非聚集數(shù)據(jù)的速度快
索引是通過(guò)二叉樹(shù)的數(shù)據(jù)結(jié)構(gòu)來(lái)描述的,我們可以這么理解聚簇索引:索引的葉節(jié)點(diǎn)就是數(shù)據(jù)節(jié)點(diǎn)。而非聚簇索引的葉節(jié)點(diǎn)仍然是索引節(jié)點(diǎn),只不過(guò)有一個(gè)指針指向?qū)?yīng)的數(shù)據(jù)塊。如下圖:
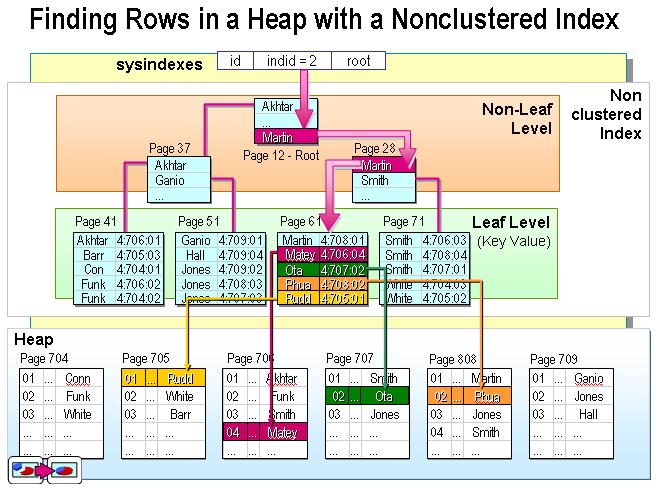
非聚集索引
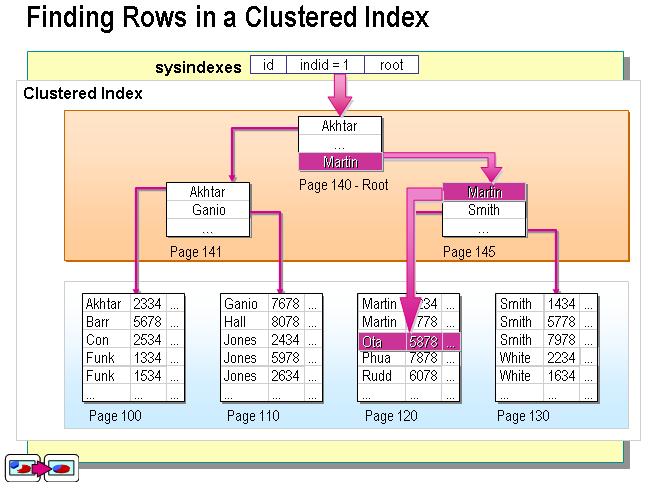
聚集索引
一、索引塊與數(shù)據(jù)塊的區(qū)別
大家都知道,索引可以提高檢索效率,因?yàn)樗亩鏄?shù)結(jié)構(gòu)以及占用空間小,所以訪問(wèn)速度塊。讓我們來(lái)算一道數(shù)學(xué)題:如果表中的一條記錄在磁盤上占用1000字節(jié)的話,我們對(duì)其中10字節(jié)的一個(gè)字段建立索引,那么該記錄對(duì)應(yīng)的索引塊的大小只有10字節(jié)。我們知道,SQL Server的最小空間分配單元是“頁(yè)(Page)”,一個(gè)頁(yè)在磁盤上占用8K空間,那么這一個(gè)頁(yè)可以存儲(chǔ)上述記錄8條,但可以存儲(chǔ)索引800條。現(xiàn)在我們要從一個(gè)有8000條記錄的表中檢索符合某個(gè)條件的記錄,如果沒(méi)有索引的話,我們可能需要遍歷8000條×1000字節(jié)/8K字節(jié)=1000個(gè)頁(yè)面才能夠找到結(jié)果。如果在檢索字段上有上述索引的話,那么我們可以在8000條×10字節(jié)/8K字節(jié)=10個(gè)頁(yè)面中就檢索到滿足條件的索引塊,然后根據(jù)索引塊上的指針逐一找到結(jié)果數(shù)據(jù)塊,這樣IO訪問(wèn)量要少的多。
二、索引優(yōu)化技術(shù)
是不是有索引就一定檢索的快呢?答案是否。有些時(shí)候用索引還不如不用索引快。比如說(shuō)我們要檢索上述表中的所有記錄,如果不用索引,需要訪問(wèn)8000條×1000 字節(jié)/8K字節(jié)=1000個(gè)頁(yè)面,如果使用索引的話,首先檢索索引,訪問(wèn)8000條×10字節(jié)/8K字節(jié)=10個(gè)頁(yè)面得到索引檢索結(jié)果,再根據(jù)索引檢索結(jié)果去對(duì)應(yīng)數(shù)據(jù)頁(yè)面,由于是檢索所有數(shù)據(jù),所以需要再訪問(wèn)8000條×1000字節(jié)/8K字節(jié)=1000個(gè)頁(yè)面將全部數(shù)據(jù)讀取出來(lái),一共訪問(wèn)了1010個(gè)頁(yè)面,這顯然不如不用索引快。
SQL Server內(nèi)部有一套完整的數(shù)據(jù)檢索優(yōu)化技術(shù),在上述情況下,SQL Server的查詢計(jì)劃(Search Plan)會(huì)自動(dòng)使用表掃描的方式檢索數(shù)據(jù)而不會(huì)使用任何索引。那么SQL Server是怎么知道什么時(shí)候用索引,什么時(shí)候不用索引的呢?SQL Server除了日常維護(hù)數(shù)據(jù)信息外,還維護(hù)著數(shù)據(jù)統(tǒng)計(jì)信息,下圖是數(shù)據(jù)庫(kù)屬性頁(yè)面的一個(gè)截圖: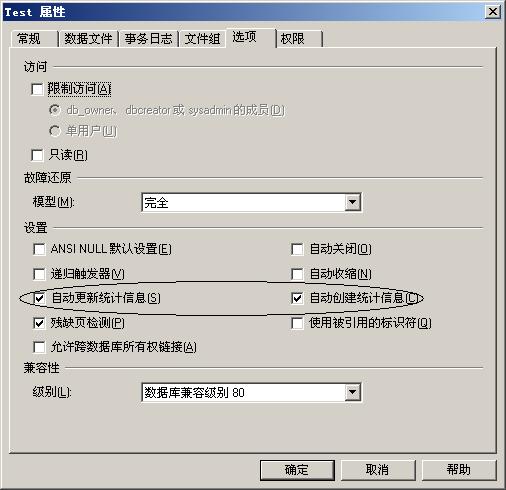
聚簇索引與非聚簇索引的本質(zhì)區(qū)別到底是什么?什么時(shí)候用聚簇索引,什么時(shí)候用非聚簇索引?
這是一個(gè)很復(fù)雜的問(wèn)題,很難用三言兩語(yǔ)說(shuō)清楚。我在這里從SQL Server索引優(yōu)化查詢的角度簡(jiǎn)單談?wù)?如果對(duì)這方面感興趣的話,可以讀一讀微軟出版的《Microsoft SQL Server 2000數(shù)據(jù)庫(kù)編程》第3單元的數(shù)據(jù)結(jié)構(gòu)引論以及第6、13、14單元)。
從圖中我們可以看到,SQL Server自動(dòng)維護(hù)統(tǒng)計(jì)信息,這些統(tǒng)計(jì)信息包括數(shù)據(jù)密度信息以及數(shù)據(jù)分布信息,這些信息幫助SQL Server決定如何制定查詢計(jì)劃以及查詢是是否使用索引以及使用什么樣的索引(這里就不再解釋它們到底如何幫助SQL Server建立查詢計(jì)劃的了)。我們還是來(lái)做個(gè)實(shí)驗(yàn)。建立一張表:tabTest(ID, unqValue,intValue),其中ID是整形自動(dòng)編號(hào)主索引,unqValue是uniqueidentifier類型,在上面建立普通索引,intValue 是整形,不建立索引。之所以掛上一個(gè)沒(méi)有索引的intValue字段,就是防止SQL Server使用索引覆蓋查詢優(yōu)化技術(shù),這樣實(shí)驗(yàn)就起不到作用了。向表中錄入10000條隨機(jī)記錄,代碼如下:
Code
it知識(shí)庫(kù):聚集索引和非聚集索引,轉(zhuǎn)載需保留來(lái)源!
鄭重聲明:本文版權(quán)歸原作者所有,轉(zhuǎn)載文章僅為傳播更多信息之目的,如作者信息標(biāo)記有誤,請(qǐng)第一時(shí)間聯(lián)系我們修改或刪除,多謝。